The State of Robotics: Emerging Trends & Commercial Frontiers, Part I

Remember Boston Dynamics' viral videos of their humanoid robot Atlas getting pushed around by engineers with hockey sticks? For years, those clips shaped our expectations of robotics — impressive physical capabilities undermined by the need for human intervention at every turn. Atlas could backflip and parkour through obstacle courses, but it couldn't pick up a pen or understand a simple voice command.
That disconnect between physical prowess and cognitive understanding has defined robotics for decades. But today, a profound shift is underway. Robots are beginning to perceive and reason about their environments with sophisticated semantic understanding — a breakthrough powered by rapid advances in learning algorithms, increasingly sophisticated hardware, and a thriving ecosystem of talent, capital, and infrastructure.
This cognitive leap is driving toward an ambitious, yet increasingly tangible, goal: general-purpose robotic intelligence. Practically, this means building robots that can perceive, reason, and act in unstructured and dynamic environments — from construction sites to commercial kitchens. The startups and tech giants racing to solve this challenge aren’t just chasing scientific breakthroughs — they’re vying to transform multibillion-dollar industries and redefine how physical work gets done.
Yet skepticism is warranted. Robotics has long been defined by persistent challenges: iRobot, maker of the Roomba and the most widely recognized consumer robotics brand, is on the verge of bankruptcy; industrial robots, while steadily advancing, still represent just a fraction of global manufacturing jobs; and autonomous vehicles have taken over a decade and tens of billions of dollars just to reach initial deployment.
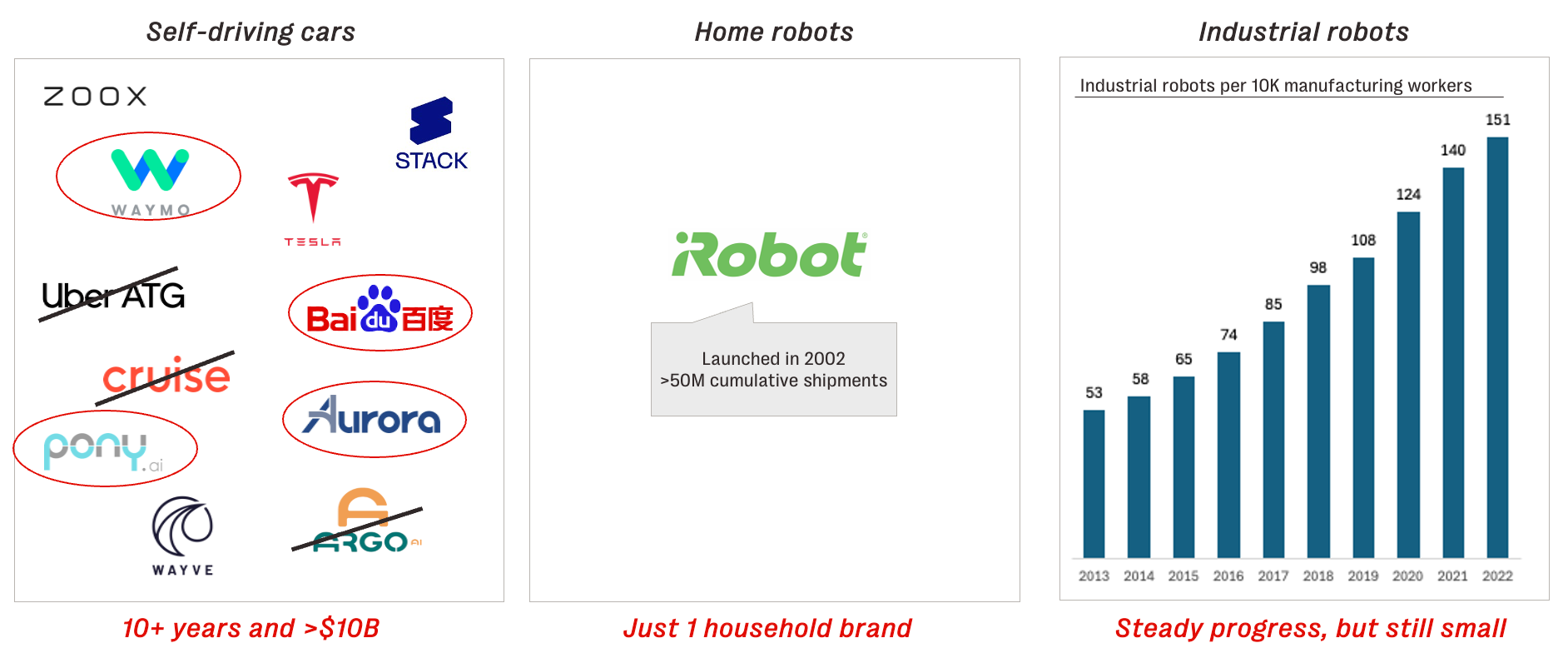
Still, there are compelling reasons to believe that we’re approaching a pivotal moment in robotics, driven by key technological advances:
Vision-language models are enabling robots to perceive and reason about their environments with a level of semantic understanding that once seemed out of reach.
Large-scale real-world demonstration datasets have made it possible to learn robust low-level robotic skills through imitation learning (though primarily in controlled settings).
Faster physics simulation capabilities have dramatically accelerated learning in virtual environments.
With these foundations in place, the next major questions come into focus: (1) How can we effectively fuse high-level semantic understanding with precise low-level motor control? (2) How can we successfully transfer learned robotic skills from (a) controlled laboratory settings to unstructured, real-world environments, and (b) from simulations to the real world? Addressing these challenges will be key to unlocking the full potential of these technological breakthroughs.
This series explores both the technical realities and strategic imperatives shaping robotics’ future. Part I examines the core technical challenges: the data collection bottleneck constraining progress, the race to develop robust policy learning algorithms, and the hardware limitations defining current boundaries. Part II shifts to the strategic questions that will determine industry structure and success — whether humanoid robots will emerge as the dominant form factor, how tightly hardware and software must integrate to achieve scale, the size of the market opportunity ahead, and which approaches seem most likely to drive scalable, transformative breakthroughs in this rapidly evolving field.
If you’re a founder building in this space, I’d love to hear from you!
1. Scaling Data Collection: The Critical Bottleneck
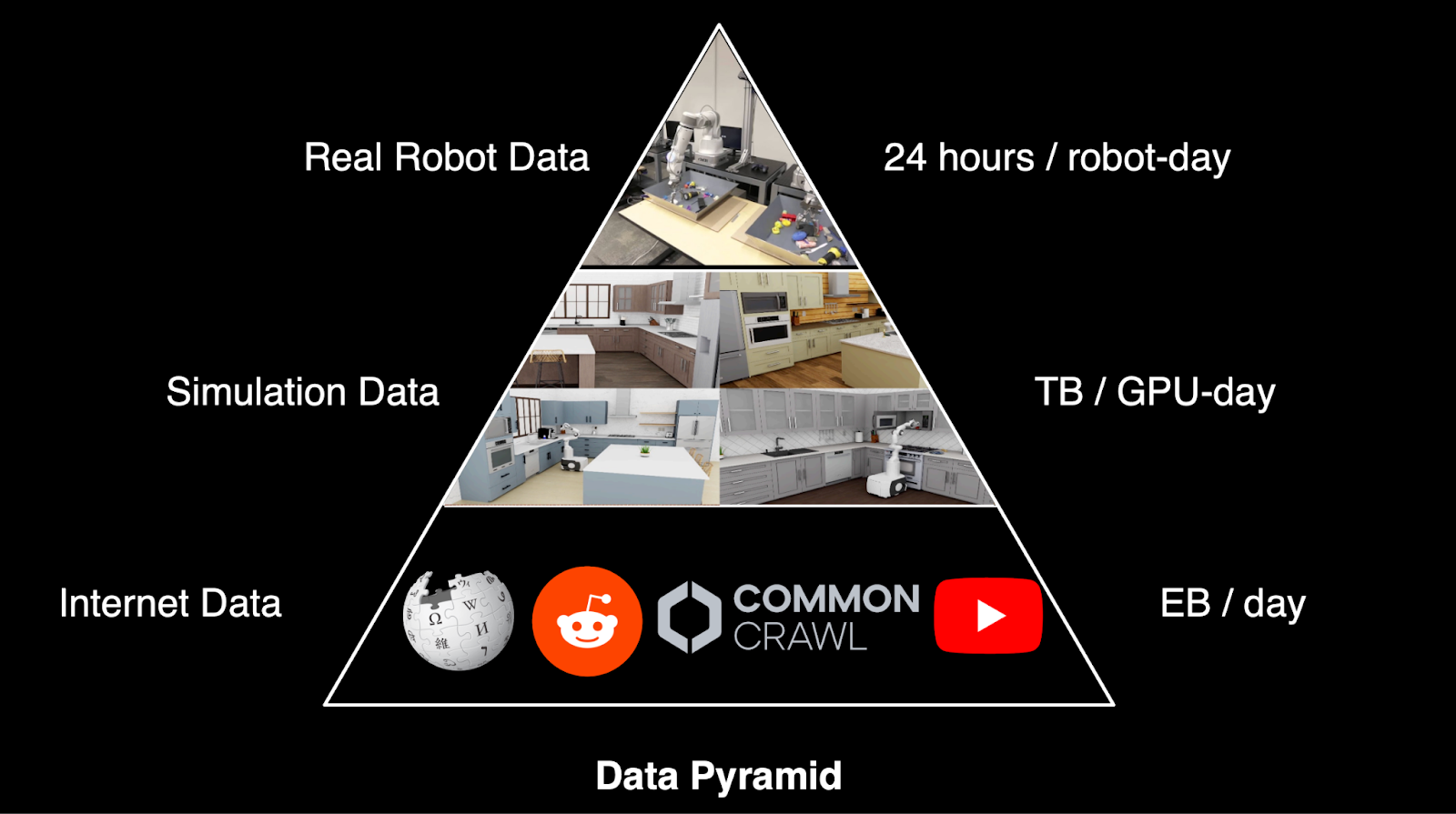
Scaling data collection is arguably the single biggest bottleneck in robotics today. Unlike Internet-scale text and image datasets that fuel large language and vision language models (LLMs and VLMs), robotics lacks any comparable large-scale dataset of real-world actions. In fact, the data gap between existing robot foundation models and mature LLMs could be up to 120,000x, as suggested by Ken Goldberg of UC Berkeley at 2025 NVIDIA GTC.

This problem is compounded by the fact that robots learn through physical interaction in high-dimensional, continuous state-action spaces. Every robot action might involve dozens of joint positions, varying forces, and complex contact dynamics — multiplied across a nearly infinite range of objects and environments. This makes both the scale and diversity of data essential for progress.
Three main approaches are emerging to tackle this challenge:
Real world demonstrations are considered the gold standard, typically collected through teleoperation (e.g., direct puppeteering, AR/VR devices, or haptics). While high-fidelity, this approach is expensive and cumbersome to scale. Projects like Open-X Embodiment and Hugging Face’s LeRobot aim to pool large scale datasets; however, existing data is largely limited to simple tasks in controlled environments, limiting applicability in real-world scenarios. Novel approaches like DOBB-E, Robot Utility Models (RUM), and Universal Manipulation Interface (UMI) aim to make data collection more accessible. DOBB-E introduced a simple iPhone attachment that lets users record household tasks from a robot’s point of view, and RUM builds on this foundation. Meanwhile, UMI uses low-cost handheld grippers to capture “in the wild” human demonstrations and convert them into robot policies that can be deployed across different hardware platforms.
Synthetic data from simulation promises virtually unlimited scale for large-scale training, but remains hampered by the persistent sim-to-real gap, stemming from fundamental limitations: difficulty modeling deformable objects, inaccurate physics and dynamics representations, constrained object diversity in simulated environments, and unstable physics solvers that compromise training reliability. While state-of-the-art simulators (Isaac Sim, MuJoCo) have been successful in locomotion, manipulation remains an unsolved challenge.
Video data, particularly egocentric (first-person) videos, represents a promising research direction, although inferring robotic actions remains difficult. Projects like UniPi use a text-guided video generator and an inverse dynamics model to extract action sequences, while Video Prediction Policy uses internal visual representations from fine-tuned video diffusion models for fast, closed loop robotic control. That said, these projects are in early stages and action translation continues to be complex and costly.
Startups are similarly taking a range of approaches to tackle this problem. Physical Intelligence (“Pi”) appears to be investing heavily in scaling up teleoperation, alongside other robot data pipelines; Skild claims to train on “1,000x more data” than competitors, likely a mix of real and synthetic data. Flexion is leaning into reinforcement learning plus simulation. Field AI employs probabilistic models to reason under uncertainty and captures rich real-world data at the edge.
Others are betting on low-cost hardware to accelerate data collection, including bimanual manipulators (Trossen, AgileX, Watney Robotics, MaxInsights), haptic devices (Roughneck), and low-cost humanoids (Feather Robotics, Reflex Robotics). Still others, like Encord, Segments, and Kognic, are focused specifically on data-labeling (alongside established players like Scale AI).
In the long run, I expect the greatest value will accrue to companies that own the entire data flywheel: data collection, model training, real-world deployment and feedback-driven refinement. Building this loop demands not just massive datasets, but also access to significant compute and infrastructure — which only the largest corporations and best-funded startups can afford. Even if simulation ultimately becomes the dominant strategy for data collection, it still hinges on a foundation of real-world data and access to substantial GPUs. And these data challenges directly inform the learning approaches being developed today.
2. Policy Learning: Bridging Perception and Action
Over the last few years, we’ve seen growing excitement around leveraging large language models (LLMs) and vision-language models (VLMs) to advance robotic perception, planning, and even control. Trained on the corpus of web multimodal data, these models are showing signs of equipping robots with broad semantic reasoning, problem solving, and generalization capabilities. When paired with robotic data to solve robotics tasks, these become robotics foundation models (RFMs), using methods like imitation learning (IL) and reinforcement learning (RL) for low-level control.
We’re seeing two distinct paradigms emerge:
Vision-Language-Action (VLA) models and imitation learning
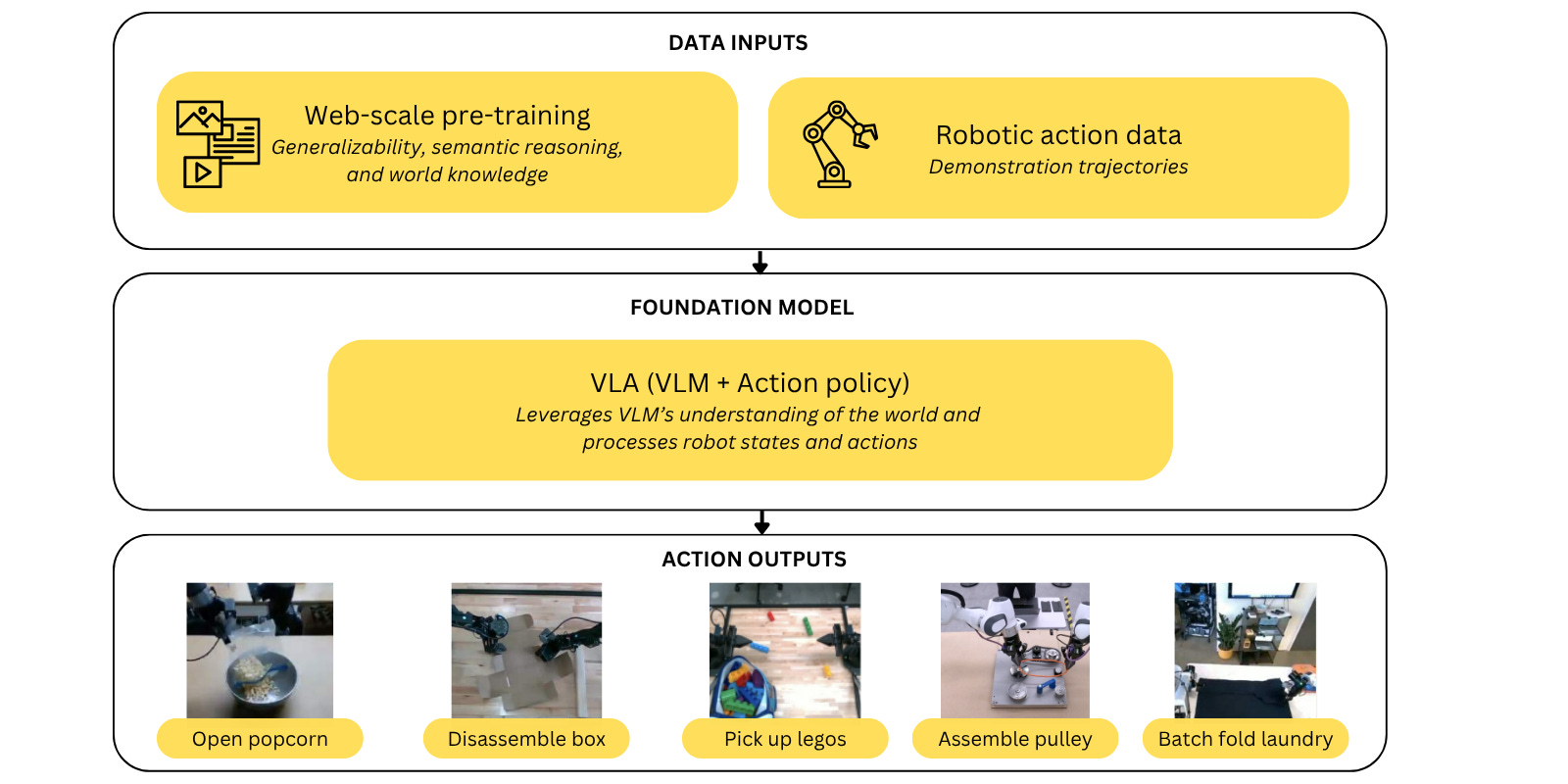
The current frontier in robotic manipulation is largely centered on vision-language-action (VLA) models — end-to-end systems that map high-level language commands and raw environment observation inputs directly into continuous actions. These models are typically trained via IL, where robots learn by mimicking human demonstrations. Early work from projects like the RT series (RT-1, RT-2, RT-X), Gemini Robotics, and Pi (π0 and π0.5) suggest several promising findings:
Combining web-scale multimodal data with robotic data enables high-level semantic and visual reasoning to guide low-level motor control, and is especially important for out-of-distribution tasks.
While scaling up data remains essential, incorporating alternative data sources —such as data from other types of robots, trajectory sketches, observations labeled with semantic behaviors, and simulated data fused with real-world data — can help reduce the cost and effort of collecting large-scale in-domain datasets. Still, determining the optimal “recipe” of data types remains an open question. For now, training VLAs remains as much an art as a science.
Although the VLA+IL approach remains the dominant paradigm for manipulation policies today, there is some skepticism about its long-term viability. Scaling real-world data collection to support IL at the required volume could demand hundreds of millions of dollars (or more) — a level of investment accessible only to a few players. Furthermore, while there has been exciting research on cross-embodiment, issues remain with transferring data across different robot morphologies and environments. While the frontier today, the VLA+IL paradigm may ultimately prove to be a stepping stone.
Reinforcement learning and simulation
RL has long held promise in robotics, offering a framework for robots to autonomously learn complex behaviors through trial and error. In locomotion, the combination of RL and simulation has unlocked impressive capabilities, where agents have learned agile quadruped and bipedal gaits, enabling robots to navigate rough terrain and recover from perturbations.
Manipulation, however, presents a steeper challenge. While RL has succeeded in training some specialist policies in narrow environments, training generalist policies in complex real world scenarios remains challenging for a few key reasons:
Exploration: Robots operate in high-dimensional, continuous state and action spaces. Rewards are often sparse or delayed, as it’s largely unclear how to design intermediate, per-step rewards that effectively guide a robot in completing a task. As a result, naive exploration through trial and error remains inefficient and potentially risky for physical systems. Imagine trying to learn to use chopsticks by random trial and error — the space of possible movements is vast, and useful actions are rare.
Sample efficiency: Unlike LLMs that train on massive static datasets, robots must learn by interacting with the physical world. Even with off-policy algorithms that reuse data, learning meaningful behaviors often takes thousands of trials, making data collection expensive and time-consuming. Furthermore, suboptimal exploratory robot actions during training can result in physical damage or require costly environment resets between episodes.
Sim-to-real transfer: Policies trained in simulation often fail in the real world due to a range of discrepancies: mismatches in physical dynamics (friction, mass), visual differences (lighting, noise), inaccuracies in sensors and actuators, and limitations in scene curation. While modern simulators can render high-quality visual inputs like images and depth maps, they are typically too slow for large-scale visual RL — though this is an active area of research. Tactile sensing is even more difficult: while it can be represented in principle, modeling it with sufficient realism remains a significant hurdle. Overcoming the sim-to-real gap will require a range of solutions, with improved scene curation playing a central role.
Future progress may hinge on creating more realistic and scalable simulation platforms, more sophisticated algorithms, and/ or leveraging generative models to reduce reliance on physical data. However, these approaches are still being researched and introduce new computational burdens.
Where is RL being used today?
There are several interesting directions in RL research today, from better reward design (EUREKA) and data bootstrapping (AutoRT), to contact-rich manipulation tasks (SERL) and even dextrous humanoid control (Lin et al.). In the startup space, Dyna Robotics is using RL on real-world manipulation tasks like napkin folding. Their system uses a nuanced reward model to infer subtask progress, enabling autonomous exploration, self-recovery, and continuous improvement without episodic resets.
World models are making a comeback
World models — which build internal representations of how the external world evolves in response to actions — are regaining popularity. While the concept isn’t new, recent progress in high-quality video generation models (Sora, Veo) has renewed excitement about their potential. The hypothesis is that sophisticated models may already encode rich knowledge about physical dynamics that robots can leverage for planning — effectively serving as learned “physics engines” that simulate and evaluate future outcomes. Their ability to generate physically consistent, high-fidelity videos also makes them valuable as visual world models, combining an understanding of how the world behaves with realistic pixel-level observations — an asset for perception-heavy tasks. That said, inferring robotic actions remains challenging. Success will ultimately depend on bridging the gap between these models' impressive visual understanding and the precise control requirements of real-world robotic tasks.
The path forward
While VLA models excel at semantic reasoning and tapping into web-scale knowledge, they remain limited by the high cost and complexity of real-world data collection. RL, by contrast, promises autonomous learning and scalability through simulation, yet remains constrained by exploration inefficiencies and the persistent sim-to-real gap. The path forward may not lie in choosing between these paradigms, but in exploring how their strengths might be combined: leveraging VLMs for semantic understanding, using IL to bootstrap RL with expert priors, tapping into video models as world simulators, or blending simulation with real-world data to enhance training diversity and robustness. The next generation of robotics foundation models will likely emerge from teams that can successfully orchestrate this convergence — aligning data, learning frameworks, and embodiment to unlock true general-purpose capabilities.
3. Hardware: The Physical Reality Check
As AI capabilities accelerate, a critical question emerges: Is hardware still a limiting factor, or are we simply not making the most of the systems we already have?
Some argue that the key to unlocking better robot performance lies not in more advanced hardware, but in more capable software — meaning that, with continued breakthroughs in learning techniques, even today’s relatively simple and affordable robots could achieve far greater capabilities. After all, sophisticated platforms like the Shadow Hand have been around for years, yet their high cost and complexity have limited real-world adoption. From this perspective, it's not better hardware we lack, but scalable, data-driven methods to fully exploit what we already have.
Others, however, contend that without sufficiently capable hardware, even the best models run into limits, especially in real-world settings. In this view, progress remains bottlenecked by sensors, actuators, and mechanical design that constrain what algorithms can realistically learn or control. The real question, then, is whether we’re held back more by the machines themselves or by our ability to teach them.
What’s clear, however, is that fundamental gaps remain between human and robot capabilities, especially in areas like system integration, dexterity and control, and sensory feedback. These gaps continue to shape not only technical progress but also business strategy.
System architecture
Beyond individual components, robots must operate as cohesive systems — and that’s where many of today’s biggest hurdles lie:
Battery life: many sophisticated robot systems (humanoids, quadrupeds) can only run for a few hours at a time, severely limiting their utility in real-world applications
Heat management: compact actuators generate significant thermal loads that can cause performance degradation or system failures over prolonged use
Manufacturing complexity and cost: Building robust platforms at scale remains expensive and slow, with complex systems requiring precision components that are expensive to produce
Dexterity and control
Many of today’s foundation models are deployed on robots with simple, gripper-based manipulators, that struggle with tasks requiring fine motor skills like sliding, twisting, or modulating force. These limitations aren’t just mechanical — they also influence how we model and describe such behaviors. Simple gripper actions are relatively easy to express in language and code, but complex, dexterous hand motions are more difficult to express or learn without richer physical interfaces.
Sensory feedback
Replicating the sense of touch is another major challenge. The human hand houses over 17,000 mechanoreceptors for sensing pressure and vibration — plus additional receptors for temperature, humidity, joint position, and even pain. Capturing this sensory richness in machines is a daunting task, both in terms of hardware and real-time data processing.
To that end, companies like Shadow Hand (mentioned above) and GelSight are developing manipulators embedded with sensors that can detect pressure, vibration, and even chemical properties. Other research efforts and startups are focused on developing full humanoid hands with integrated vision-based tactile sensors. However, even if we haven’t hit the upper bounds of existing hardware, cost, scalability, and reliability remain significant issues.
That said, the cost curves are beginning to bend in robotics’ favor. The average price of an industrial robot has halved in the past decade, GPUs continue to improve in price-performance ratio, and estimates suggest that Bill of Materials (BoM) costs for general-purpose humanoids will drop significantly in the next 5-10 years. As costs decline and access expands, hardware innovation will become both more feasible and more attractive.
Ultimately, the trajectory of robotics will be shaped by the interplay between hardware and software. While recent progress in learning suggests we may not need radically better hardware to achieve useful capabilities, continued improvements in cost, integration, and sensory fidelity will expand what’s possible — and make those possibilities economically viable. The divide is no longer purely technical, but strategic: some well-funded players are pursuing vertically integrated systems, while others are betting on generalized software built atop off-the-shelf platforms. Whichever path they pursue, hardware remains the medium through which intelligence meets the physical world.
The technical foundations are coming into view — but the strategic frontier is just as important. In Part II, I’ll dive into the commercial and structural forces shaping robotics: form factor bets, integration decisions, platform dynamics, and the race to capture value. Stay tuned!
Wow! That is an impressive level of detail you have there. Thank you for it.
It’s good to read up on the state of robotics. I’ve been publishing an article series the past month entitled “The Long Tomorrow” that examines a whole host of tough questions at the intersection of longevity and AI / robotics. If that piques your interest any, I’d love to hear and read your thoughts!